Para su estudio, la estadística se divide en: Estadística Descriptiva e Inferencia Estadística.
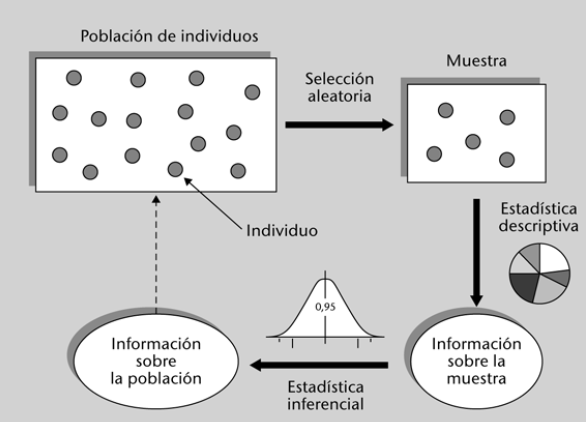
La Primera se encarga de la recopilación, organización, resumen y presentación de los datos numéricos obtenidos de la observación de un fenómeno; mientras que la Segunda tiene por objeto, obtener conclusiones probables sobre el comportamiento general del fenómeno, a partir de algunas observaciones particulares del mismo.
Para obtener una muestra representativa, existen diferentes técnicas, entre las cuales se encuentran las siguientes:
- Muestreo Aleatorio. Consiste en formar una lista de los elementos de la población, enumerarlos y hacer selección, mediante selección de números aleatorios con distribución uniforme, recomendable para muestras pequeñas.
- Muestreo Sistemático. Se listan los elementos de la población, pero en lugar de seleccionar de manera aleatoria, se recorre la muestra seleccionando cada k-ésimo elemento.
- Muestreo Estratificado. La población se divide en clases o estratos para posteriormente hace una selección aleatoria o sistemática dentro de cada estrato.
- Muestreo por Conglomerados. Semejante al estratificado pero se aplica cuando la población es homogénea y existen grupos ya definidos.
Clasificación y Organización de los datos de una muestra.
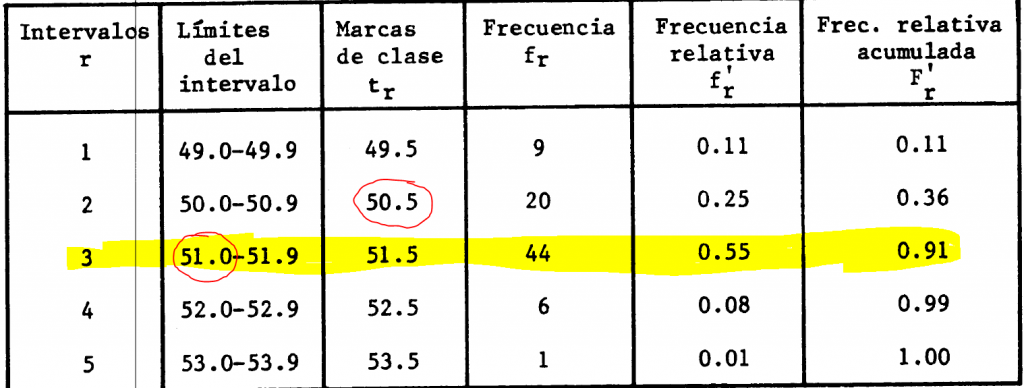
Se debe calcular el Rango de la muestra que se define como la diferencia entre el mayor y el menor de los elementos
Rango = 53.1 – 49.1 = 4.0
Para ordenar los 80 datos, se clasifican en intervalos, llamados Intervalos de Clase. Se recomienda establecer entre 5 y 15 intervalos
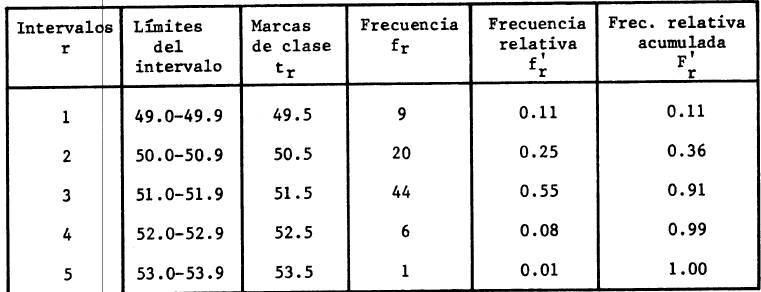
Al numero de elementos de la muestra que pertenece a un intervalo de clase r se le llama Frecuencia de Intervalo y se representa como fr. La suma de las frecuencias deberá ser igual al número total de elementos de la muestra de tamaño n
Para representar las frecuencias o frecuencias relativas se usa generalmente el Histograma o el Polígono de frecuencias
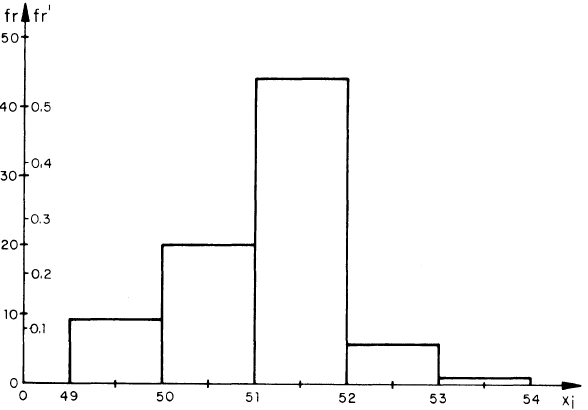
Polígono de Frecuencia
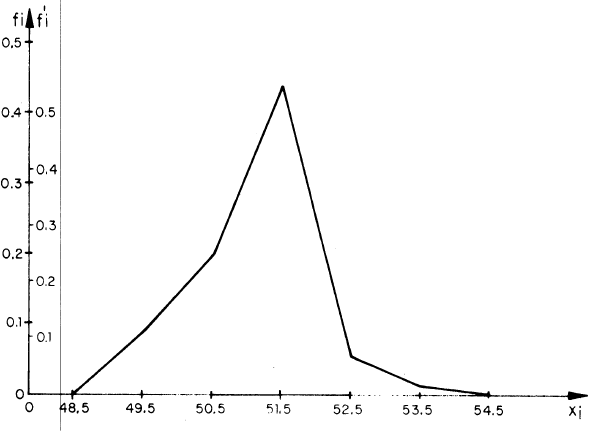
Polígono de frecuencias relativas acumuladas
Medidas estadísticas
La Media o la Varianza son ejemplo de indicadores que se representan mediante las letras griegas μ, σ, ρ, etc., y se les llama parámetros. En el caso de una distribución de frecuencias también se pueden establecer medidas descriptivas y para distinguirlas de los parámetros, se usan letras latinas como x, s, r, etc.
Generalmente se utilizan 4 tipos de medidas descriptivas:
- De tendencia Central
- De dispersión
- De sesgo o asimetría
- De curtosis o apuntamiento
Medidas de Tendencia Central:
Media(![]() ). Se define como el promedio aritmético de los datos de una muestra. Para diferenciarla de la media de la población se representa con
). Se define como el promedio aritmético de los datos de una muestra. Para diferenciarla de la media de la población se representa con ![]() .
.
Mediana(Me). Es el valor que corresponde a la mitad de los datos ordenados de una muestra
Moda o Modo(Mo). El elemento de la muestra que tiene más frecuencia, es decir, el que más se repite. puede haber mas de una moda(bimodal o multimodal). Cuando todos los elementos son diferentes, la moda no existe o todos son la moda
Medidas de Dispersión:
Rango. indica la máxima separación entre los datos.
Varianza. nos da una medida de dispersión relativa al tamaño muestral
Desviación típica o estándar: la raíz cuadrada de la varianza.
Coeficiente de variación. El cociente de la Desviación estándar muestral entre la media muestral:
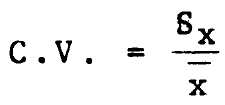
Medidas de Asimetría. No atenderemos esta de momento
Medidas de curtosis o apuntamiento. No atenderemos esta de momento
Distribuciones probabilísticas
Una variable cuyo valor está determinado por el resultado de un experimento u observación es una variable aleatoria. Los valores que toma una variable aleatoria se asocian con eventos aleatorios, en el espacio muestral de un experimento realizado.
Existen dos clases de variables aleatorias.
- Discretas
- Continuas
Definición Una variable aleatoria es una regla bien definida para asignar valores numéricos a todos los resultados probables de un experimento. A todo valor de una variable aleatoria corresponderá una probabilidad. Ese conjunto de todos los valores posibles recibe el nombre de función o distribución de probabilidad de la variable aleatoria.
Distribución Binomial.
Nos encontramos con un modelo derivado de un proceso experimental puro, en el que se plantean las siguientes circunstancias
- Se realiza un número n de pruebas (separadas o separables).
- Cada prueba puede dar dos únicos resultados A y Ã
La probabilidad de obtener un resultado A es p y la de obtener un resultado à es q, con q= 1-p, en todas las pruebas. Esto implica que las pruebas se realizan exactamente en las mismas condiciones y son , por tanto, independientes en sus resultados. Si se trata de extracciones, (muestreo), las extracciones deberán ser con devolución (reemplazamiento) , o bien población grande.
Ejemplo:
Supongamos que una ciudad hay 1,000,000 de habitantes de los cuales 450,000 son varones y 550,000 son mujeres . Si extraemos un individuo al azar la probabilidad. de que sea mujer será.
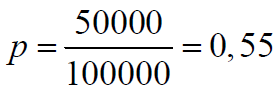
Si repetimos esta prueba varias veces y no reponemos «en el saco» al sujeto extraído la probabilidad de obtener una mujer en cada siguiente extracción variará, al variar la composición por sexos de la población restante. Sin embargo, al ser la población tan grande, la variación de esta probabilidad con cada sucesiva prueba será prácticamente despreciable y podremos considerar, en la práctica que las probabilidades
son constantes: en efecto: Si, en la primera prueba obtenemos una mujer y no la reintegramos a la población la de probabilidad de obtener una mujer en la segunda prueba será:
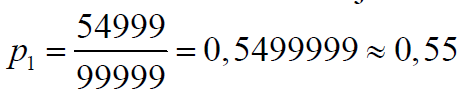
Si por el contrario en la primera prueba se obtiene un varón la probabilidad de obtener una mujer el siguiente será:
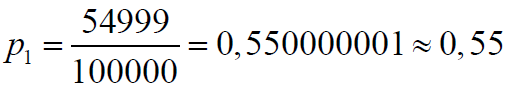
Sin embargo, si la población es pequeña, las variaciones de la probabilidad de éxito con cada prueba serán importantes sino se devuelve a la población original cada sujeto extraído .En este caso, no podremos considerar que p y q son constantes a lo largo de todo el proceso y el número de éxitos obtenidos en n pruebas será una variable aleatoria que no seguirá una distribución binomial sino una nueva distribución llamada hipergeométrica
Distribución Normal
La distribución normal es con referencia a la población, sin duda, la más conocida y usada de todas. Muchos fenómenos naturales tienden a dar como resultado una distribución normal. Entre otras, longitud, altura y grosor de animales o plantas; mediciones de cantidades de azúcar en la sangre; cantidad de glóbulos blancos; incidencia de las enfermedades del oído interno y medidas en el aspecto conductista, emocional o psicológico de las acciones, aptitudes o capacidades humanas. La distribución de los errores de medida (desviaciones en relación con un valor específico en los diámetros de pistones, cilindros o cañones de armas de fuego; pesos de productos empaquetados e incluso las longitudes de las cintas métricas) tiende a ser normal, al igual que la distribución del grado de perfección de diversos procesos de producción.
La distribución normal es continua, ahí la variable aleatoria X es capaz de adoptar cualquier valor comprendido en el siguiente intervalo
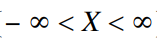
Dos parámetros describen la distribución normal:
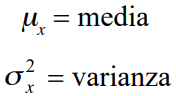
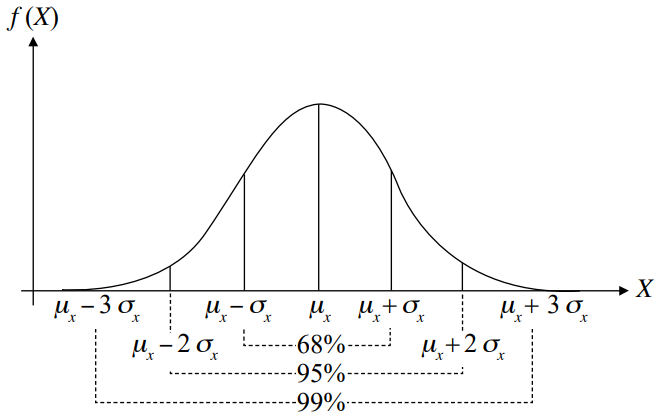
El área bajo la curva se llama masa de probabilidad o simplemente probabilidad. Ésta se calculará por medio de tablas, (Z).
Distribución Z
Si una variable X (puntuaciones, datos, calificaciones, etc.) se halla normalmente distribuida, entonces, las estadísticas tipificadas o estandarizadas estarán definidas por:
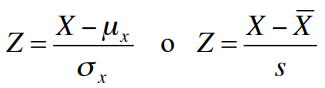
Link a Ejemplo y ejercicios de Distribución Normal
Distribución de Poisson – Link
Ejercicios de Distribución de Poisson – Link
Ejemplos
Ejemplo 1 de Media
El número de autos que se venden semanalmente en una agencia distribuidora se ha registrado durante 10 semanas con los siguientes resultados:
2, 5, 3, 4, 4, 4, 5, 1, 1, 3
¿Cuál es la media muestral?
como la muestra es pequeña, no es necesario agrupar los datos en una tabla de frecuencias y se puede usar directamente la expresión:
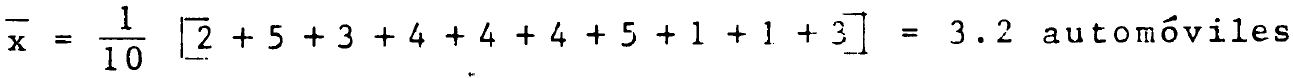
Ejemplo 2 de Media
Encontrar la media de los siguientes datos.
Debido a que los datos están agrupados
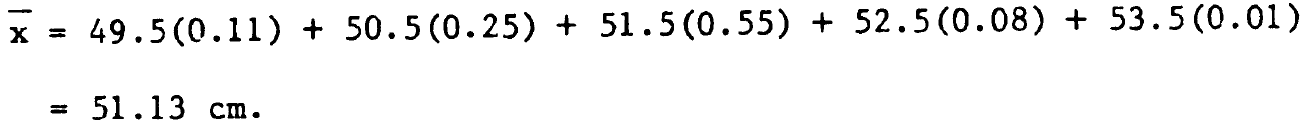
Ejemplo 1 Mediana. ¿cuál es la mediana de los datos: 2, 5, 3, 4, 4, 4, 5, 1, 1, 3?
ordenando los elementos de manera ascendente: 1, 1, 2, 3, 3, 4, 4, 4, 5, 5.
como son 10 elementos, la mediana se encuentra entre el quinto(3) y el sexto elemento(4), por lo cual:
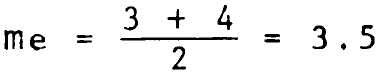
Ejemplo 2 Mediana
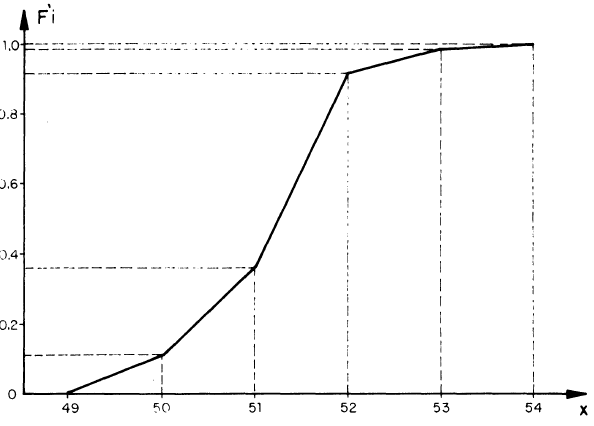
Cuando la muestra es grande y sus elementos se encuentran agrupados, la mediana puede obtenerse determinando primero al intervalo que contiene a la mediana, el cual se distingue porque es el primero que tiene una Frecuencia relativa acumulada mayor o igual a 0.5 y posteriormente, mediante una interpolación lineal se encuentra el valor de x que corresponde a la frecuencia relativa acumulada de 0.5.